Direct identifiers and indirect identifiers form two primary components for identification of individuals, users, or personal information.
Direct identifiers are fields that uniquely identify the subject (usually name, address, etc.) and are usually referred to as personally identifiable information. Masking solutions are usually used to protect direct identifiers.
Indirect identifiers typically consist of demographic or socioeconomic information, dates, or events. While each standalone indirect identifier cannot identify the individual, the risk is that combining several indirect identifiers together with external data can result in exposing the subject of the information. For example, imagine a scenario where users were able to combine search engine data coupled with online streaming recommendations to tie back posts and recommendations to individual users on a website.
Anonymization is the process of removing the indirect identifiers to prevent data analysis tools or other intelligent mechanisms from collating or pulling data from multiple sources to identify an individual or sensitive information. The process of anonymization is like masking and includes identifying the relevant information to anonymize and choosing a relevant method for obscuring the data. Obscuring indirect identifiers is complicated by this type of data’s ability to be integrated in free text fields, which tend to be less structured than direct identifiers.
Tokenization
Tokenization is the process of substituting a sensitive data element with a non-sensitive equivalent, referred to as a token. The token is usually a collection of random values with the shape and form of the original data placeholder that is mapped back to the original data by the tokenization application or solution.
Tokenization is not encryption and presents different challenges and different benefits. Encryption is using a key to obfuscate data, while tokenization removes the data entirely from the database, replacing it with a mechanism to identify and access the resources.
Tokenization is used to safeguard sensitive data in a secure, protected, or regulated environment.
Tokenization can be implemented internally where there is a need to secure sensitive data centrally or externally using a tokenization service.
Tokenization can assist with:
- Complying with regulations or laws
- Reducing the cost of compliance
- Mitigating risks of storing sensitive data and reducing attack vectors on that data
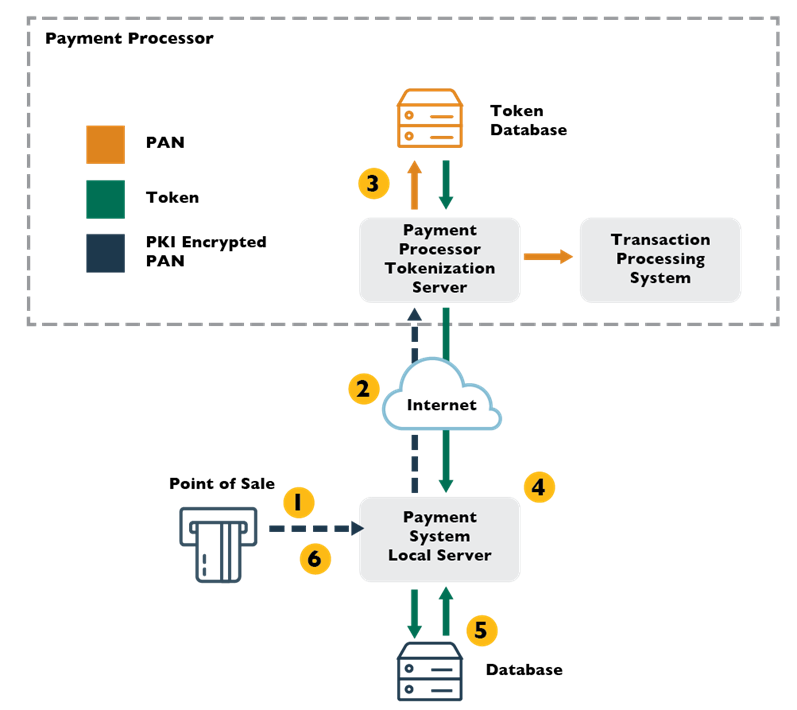
Basic Tokenization Architecture
The basic tokenization architecture involves the following six steps:
- An application collects or generates a piece of sensitive data.
- Data is sent to the tokenization server—it is not stored locally.
- The tokenization server generates the token. The sensitive data and the token are stored in the token database.
- The tokenization server returns the token to the application.
- The application stores the token, rather than the original data.
- When the sensitive data is needed, an authorized application or user can request it.
Tokenization and Cloud Considerations
Keep the following in mind:
- When using tokenization as a service, it is imperative to ensure the provider’s and solution’s ability to protect your data. Note that you cannot outsource accountability!
- When using tokenization as a service, special attention should be paid to the process of authenticating the application when storing or retrieving sensitive data. Where external tokenization is used, appropriate encryption of communications should be applied to data in motion.
- As always, evaluate your compliance requirements before considering a cloud-based tokenization solution. The risks of having to interact with different jurisdictions and different compliance requirements will need to be weighed.