Data security is a core element of cloud security. Cloud service providers often share the responsibility for security with the customer. Roles such as the chief information security officer (CISO), chief security officer (CSO), chief technology officer (CTO), enterprise architect, and network administrator may all play a part in providing elements of a security solution for the enterprise.
The secure data lifecycle enables the organization to map the different phases in the data lifecycle against the required controls that are relevant for each phase.
The data lifecycle guidance provides a framework to map relevant use cases for data access, while assisting in the development of appropriate controls within each lifecycle stage.
Note that the lifecycle model serves as a reference and framework to provide a standardized approach for data lifecycle and data security. Not all implementations or situations will align fully or comprehensively.
The Secure Data Lifecycle
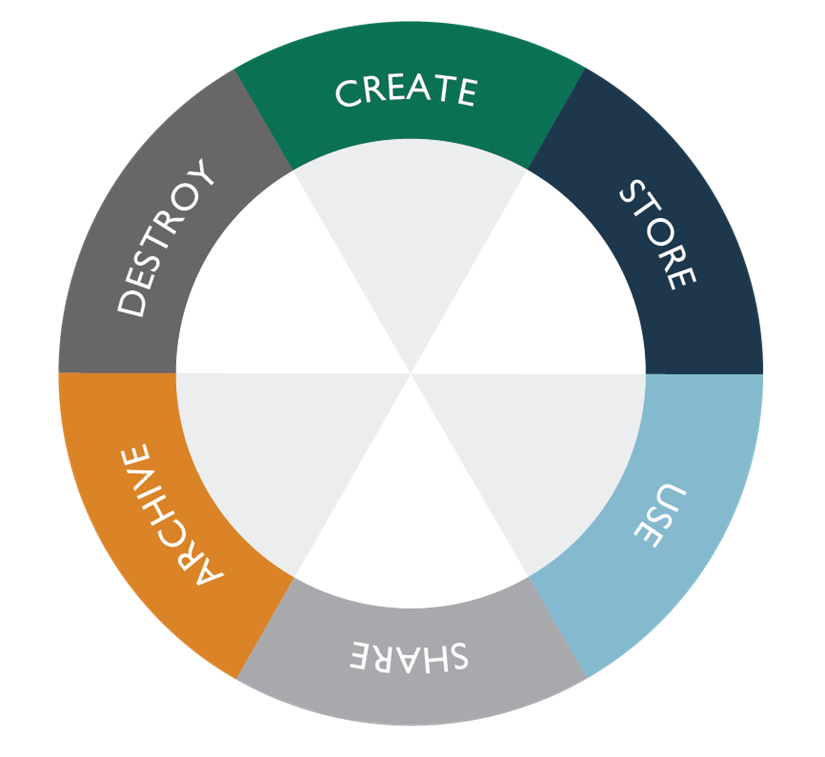
The secure data lifecycle comprises six different phases, from creation to destruction. While the lifecycle is described as a linear process, data may skip certain stages, or even switch back and forth between the different phases. The six phases of the data lifecycle are:
- Create: Digital content is initially generated or acquired. Versioning or the modification of existing content is also considered creation. This can be done within the cloud or imported from an external source.
- Store: Placement of digital data into a repository. Initial storage is usually done immediately after creation. When stored, data should be protected based on organizational policies regarding classification level, security controls, access policy, and monitoring requirements. Alternate storage locations, or backups, should be used to avoid data loss.
- Use: Digital data or information is viewed, processed, or used. This is the most vulnerable stage for data because it can be transported to insecure locations. Controls like data loss prevention (DLP), data rights management (DRM), and data access monitors should be implemented. Audit trails should be established to prevent unauthorized access.
- Share: Data and information is made accessible to others. Not all data should be shared, and not all sharing should present a threat. Technologies like DLP and DRM are typically used to detect unauthorized sharing and maintain control over the information.
- Archive: When data is no longer needed to support active processes, it is placed into long-term storage called an archive. Cost and availability considerations can affect data access procedures. Continually changing technologies can also have a major impact on desired archiving formats. Archived data must continue to be protected in compliance with organizational policies and regulatory requirements.
- Destroy: In this last phase of the lifecycle, data is removed from the cloud service provider. Depending on usage, data content, policies and regulations, and applications used, the technical means employed will vary—for example, from logical erasure of pointers to permanent data destruction by physical or digital means. Consideration should be given to regulations and compliance, type of cloud being used (IAAS versus SAAS), and the classification of the data.
The creation phase is the preferred time to classify content according to its sensitivity and value to the organization. Careful classification is important because poor security controls could be implemented if content is classified incorrectly.
Organizational information management policies address how data is handled through all subsequent phases. These policies should address things such as: What activities are allowed for different information types? Where can data be geographically located? And are there any legal or regulatory implications if the data is mishandled? Data governance policies also dictate who is allowed to access different types of information.
Data governance should also address data custodianship, which specifically identifies who is responsible for managing the information at the behest of the owner.
While the lifecycle does not require the specification of data location, who can access it, and from where, you need to fully understand and incorporate location and access into your planning for the use of the lifecycle within the enterprise.
Location
Data is a portable resource, capable of moving swiftly and easily between different locations both inside and outside of the enterprise. It can be generated in the internal network, moved into the cloud for processing, and then moved to a different provider for backup or archival storage. The international nature of cloud computing is also a major system design aspect. The broad adoption of cloud, coupled with its importance to national information technology industry growth, has led to a proliferation of national laws and regulations regarding cross-border transfer of data. This makes location of a data source versus the location of the data sink a critical aspect of modern business.
Data Dispersion in Cloud
When data is dispersed internationally or even between different legal jurisdictions within the same country, many new data management and control issues are raised. In the United States, for instance, the lack of a national data privacy law has led its legally sovereign states to pass their own. This has led to a patchwork of privacy and data protection laws within the country, making it very difficult for enterprises to set effective data governance strategies.
To provide high data availability, assurance, and performance, storage applications will often use the data dispersion technique. For this technique, each storage block is fragmented and the storage application writes each bit into different physical storage containers to achieve greater information assurance, just like the old-fashioned RAID system, only scattered across different physical devices.
The underlying architecture of this technology involves the use of erasure coding, which chunks a data object (think of a file with self-describing metadata) into segments. Each segment is encrypted, cut into 16 slices, and dispersed across an organization’s network to reside on different hard drives and servers. If the organization has access to only 10 of the slices—because of disk failures, for instance—the original data can still be put back together. If the data is generally static with very few rewrites, such as media files and archive logs, creating and distributing the data is a one-time cost. If the data is very dynamic, the erasure codes have to be re-created and the resulting data blocks redistributed.
Here are some key questions to ask –
- Who are the actors that potentially have access to data I need to protect?
- What are the potential locations for data I have to protect?
- What are the controls in each of those locations?
- At what phases in each lifecycle can data move between locations?
- How does data move between locations (via what channels)?
- What are the relevant data sovereignty laws, if any?
- Where are these actors coming from (what locations, and are they trusted or untrusted)?
Next article in series – Data Security: Functions, Actors, and Locations
1 thought on “Data Security : The Secure Data Lifecycle”